文本处理
正则表达式
匹配单个字符
| 字符 |
功能 |
| . |
匹配任意一个字符(除了\n) |
| [] |
匹配 [] 中列举的字符 |
| \d |
匹配数字,即 0-9 |
| \D |
匹配非数字 |
| \s |
匹配空白,即 空格、tab键 |
| \S |
匹配非空白 |
| \w |
匹配单词字符,即 a-z、A-Z、0-9、_ |
| \W |
匹配非单词字符 |
匹配多个字符
| 字符 |
功能 |
| * |
匹配前一个字符出现 0 次或无限次 |
| + |
匹配前一个字符出现 1 次或无限次 |
| ? |
匹配前一个字符出现 0 次或 1 次 |
| {m} |
匹配前一个字符出现 m 次 |
| {m,n} |
匹配前一个字符出现 m 到 n 次 |
匹配开头或结尾
| 字符 |
功能 |
| ^ |
匹配字符串开头 |
| $ |
匹配字符串结尾 |
- | 匹配左右任一个表达式。yours|mine|his
- [\text{^}] \text{^}在方括号内表示非后面的字符。[\text{^A-Z}]
pat = re.compile(pattern),创建模式对象pat,以后只要用 pat.match 等自己的方法。
match(pattern,string),从字符串开始处匹配模式,返回第一个匹配上的。
group(i)。匹配分组,group(0) 为整个匹配上的串。
1
2
3
4
5
6
| import re
s = "bdsbfhsa121321"
print(re.search(r"(\D+)(\d+)", s).group(0))
|
search(pattern,string),从字符串每个位置开始,返回第一个匹配上的。
由于match和search返回的是_sre.SRE_Match格式,所以要配合group使用。
split(pattern,string),把string用pattern分割,返回列表。
sub(pat,repl,string),把string中所有pat的匹配项替换为repl,返回新字符串。
findall(pattern,string),找到所有匹配,返回列表。
词干提取和词形还原
词干提取是去词的前后缀,抽取词的词干或词根,不一定能表达完整的语义,方法较为简单,例如 leave - leav。
词形还原是把一个词汇还原为一般形式,能够表达完整语义,例如 leave - leaf,方法较为复杂,需要词性标注标签。
中文分词
基于规则的分词方法:依据词典进行分词
- 正向最大匹配:从左到右贪心选择尽量长且在词典中的词,删除,再继续。词典中始终没有就自成一词。
- 逆向最大匹配:从右到左贪心选择尽量长且在词典中的词,删除,再继续。词典中始终没有就自成一词。注意词典中词也反过来了。
- 双向最大匹配:上述两种算法都做一遍,根据:长词越多越好,非词典词和单字词越少越好,总词数越少越好。选择一种方案作为结果。
- 结巴分词
基于统计的分词方法
文本分类
定义
文本分类是将自然语言的文本(例如,网页,电子邮件,新闻,公司文档等)归入到预定义的语义类别中。
作用
- 文本分类组织,便于管理、归档、检索和维护
- 垃圾邮件过滤
分本分类的类别
- 文本内容分类。时事,财经,体育,军事等。
- 文本情感分类。称赞批评,风险机会,电商评论,政治立场等。
- 文本题材分类。个人主页,新闻,评论,科技文献等。
基本流程
- 预处理。去掉特殊字符、标点等,分词,去停词,取词干,删去低频词。
- 词包
- 特征选择
- 构建分类器
朴素贝叶斯
P(Y=y∣X=x)=P(X=x)P(Y=y)⋅P(X=x∣Y=y)=∑yP(Y=y)P(X=x∣Y=y)P(Y=y)⋅P(X=x∣Y=y)
似然:P(X=x∣Y=y)
先验概率:P(Y=y)
后验概率:P(Y=y∣X=x)
取后验概率最大的标签 y。
平滑
add−α:
P(xi∣y)=ny+Vαni,y+α
不同 αi:
P(xi∣y)=ny+∑j=1Vαjni,y+αi
评估标准
Accuarcy(准确率)
TP+TN+FP+FNTP+TN
Precision(精确率)
选中的项中正确的概率
TP+FPTP
Recall(召回率)
正确的项被选中的概率
TP+FNTP
F1
F=(P+R)2PR
语言模型
用途
- 计算句子正确的概率
- 决定哪个词序列的可能性更大
- 已知若干词,预测下一个词
应用
语音识别,上下文敏感的拼写检查,机器翻译,手写体识别,OCR(光学字符识别)
目标
计算词序列的概率
P(W)=P(w1,w2,⋯,wn)
链式法则
P(w1,w2,⋯,wn)=i∏P(wi∣w1w2⋯wi−1)
马尔科夫假设
一阶马尔科夫假设:
P(xi∣x1,⋯,xi−1)≈P(xi∣xi−1)
二阶马尔科夫假设:
P(xi∣x1,⋯,xi−1)≈P(xi∣xi−2,xi−1)
N-gram语言模型
Unigram Model
P(w1,⋯,wn)=i∏P(wi)
Bigram Model
基于一阶马尔科夫假设
P(w1,⋯,wn)=i∏P(wi∣wi−1)×P(STOP∣wn)
Trigram Model
基于二阶马尔科夫假设
P(w1,⋯,wn)=i∏P(wi∣wi−2,wi−1)×P(STOP∣wn−1,wn)
总结
深度学习可以视为无穷元语法。
更大的n:对下一个词出现的约束信息更多,有更大的辨别力。
更小的n:在语料库中出现的次数更多,具有更可靠的统计信息,具有更高的可靠性。
评估
Perplexity(困惑度)
perplexity=NP(w1,⋯,wn)1
平滑
add−α,Interpolation(插值法),Kneser-Ney smoothing
Interpolation(插值法)
P(wi∣wi−2,wi−1)λ1+λ2+λ3=1=λ1P(wi∣wi−2,wi−1)+λ2P(wi∣wi−1)+λ3P(wi)
Kneser-Ney smoothing
P(wi∣wi−1)=c(wi−1)max{c(wi−1,wi)−d,0}+λ(wi−1)PCONTINUATION(wi)PCONTINUATION(w)=∣v′,w′∈V:c(v′,w′)>0∣∣v∈V:c(v,w)>0∣
拼写检查
- Non-word Errors:错误词不在词典中。
- Real-word Errors:错误词在词典中。
噪声信道模型
最短编辑距离
dp[i][j] 表示 串S前 i 个字符,串T前 j 个字符的最短编辑距离。
dp[i][0]=idp[0][j]=j
dp[i][j]=min⎩⎨⎧dp[i−1][j]+1dp[i][j−1]+1dp[i−1][j−1]+2⋅[Si=Tj]
流程
prob of candidate=P(candidate∣W)⋅P(mistake∣candidate)
结合语言模型求解 P(candidate∣W)。
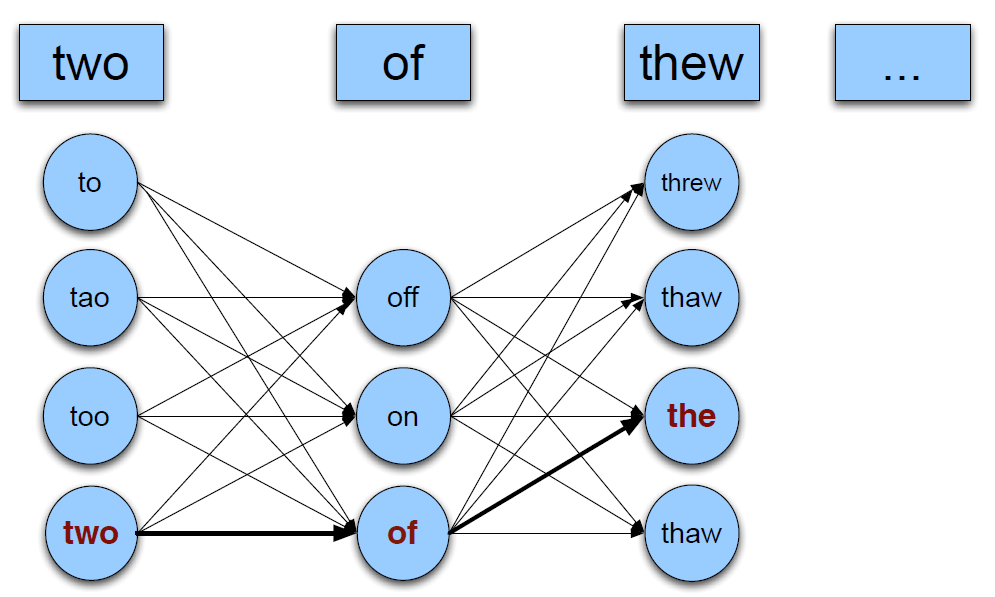
- 对于错误的词,根据编辑距离生成候选词,常选距离为 1 或 2 的词。
- 对于 real-word Errors 需要对每个词都生成候选词。如上图。
- 根据给定文本库计算 P(mistake∣candidate)。
- 根据语言模型(unigram/bigram/trigram/···),计算 P(candidate∣W),例如 bigram,P(candidate∣W)≈P(candidate∣wi−1)。
- 选出 prob of candidate 最高的词作为修改词。
词的语义表示
词向量
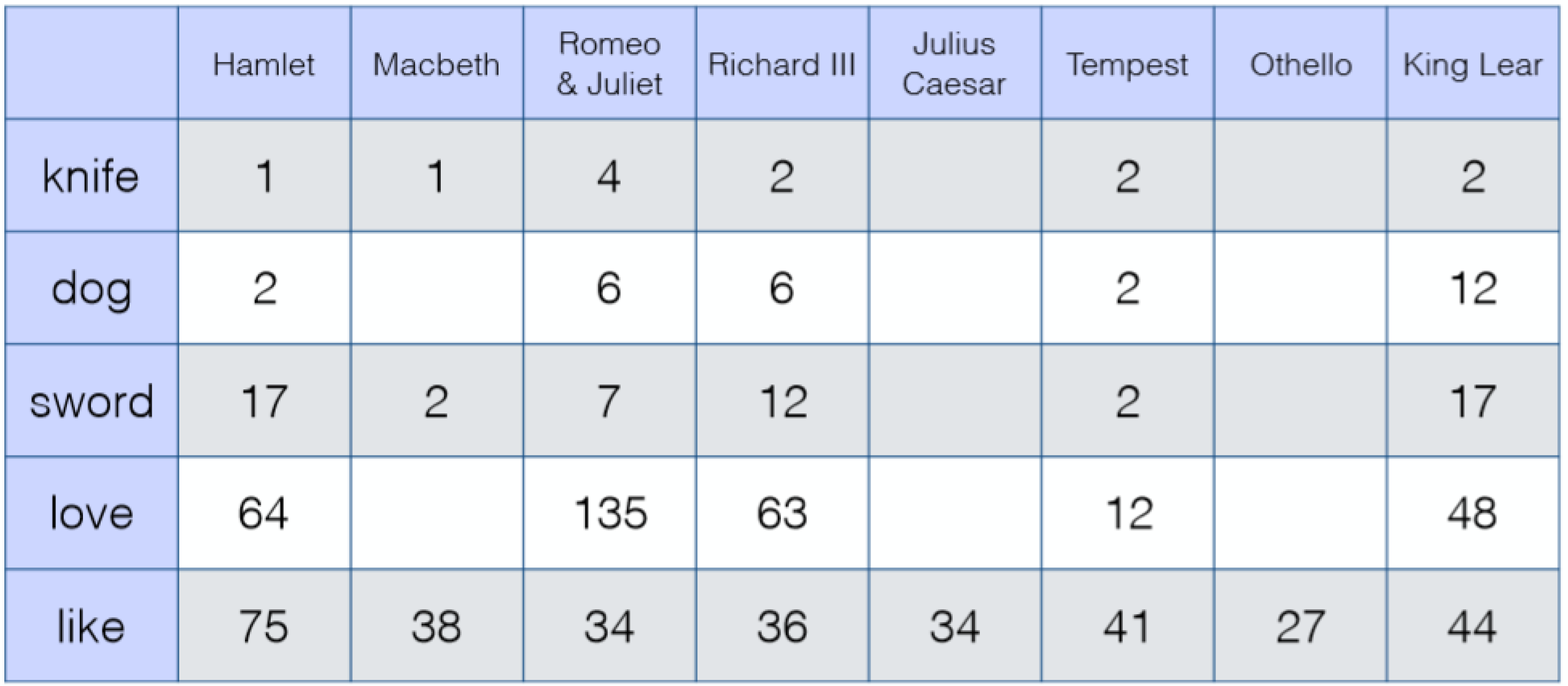
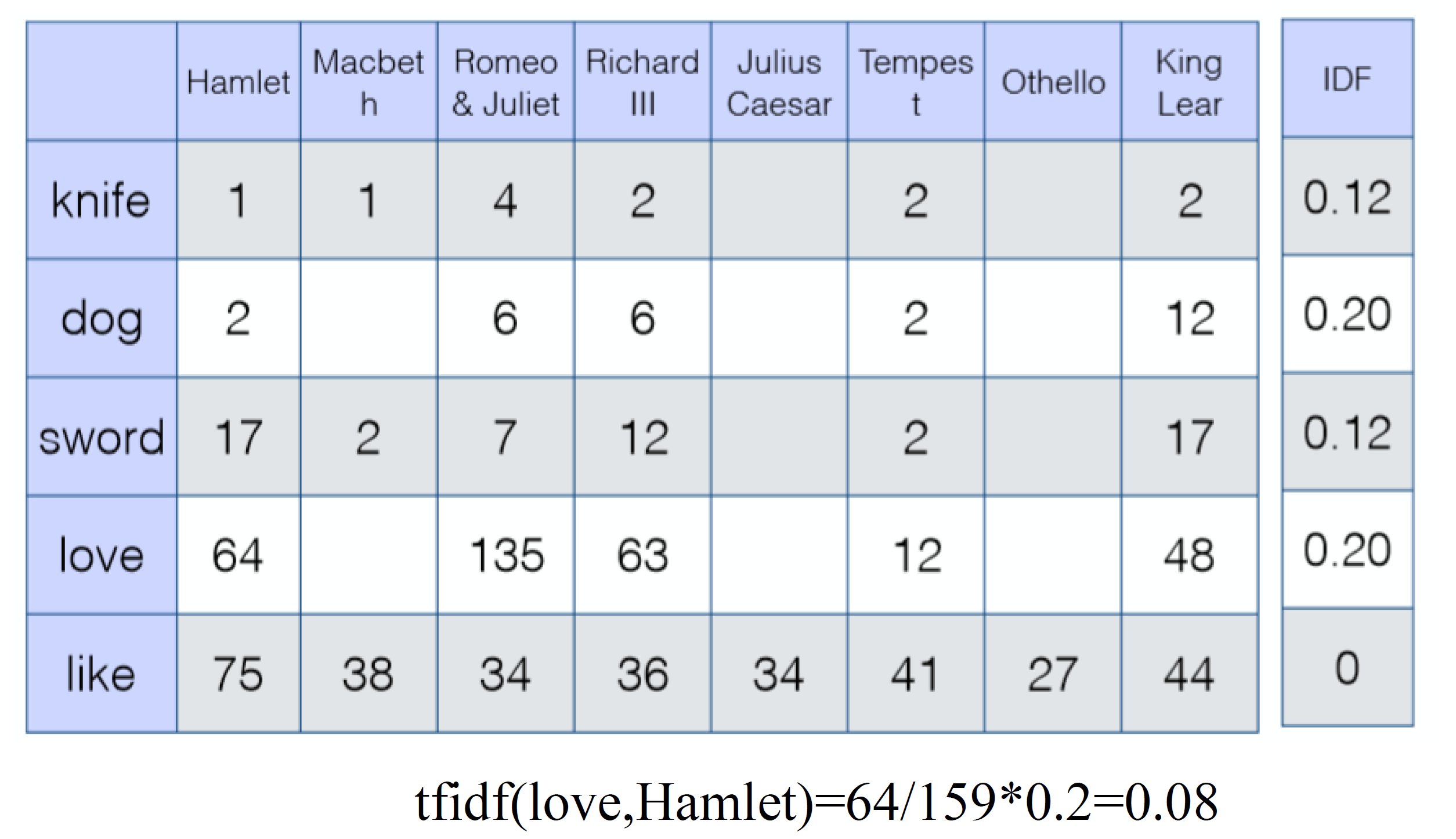
TF-IDF
针对 Term-document
tfi,j:单词 i 在文档 j 中出现的频率,即单词 i 在文档 j 中出现次数 / 所有单词在文档 j 中出现次数之和。
tfi,j=∑knk,jni,j
idfi:总文档数 / 包含单词 i 的文档数。
idfi=log∣d:ti∈d∣∣D∣
tfidfi,j=tfi,j⋅idfi
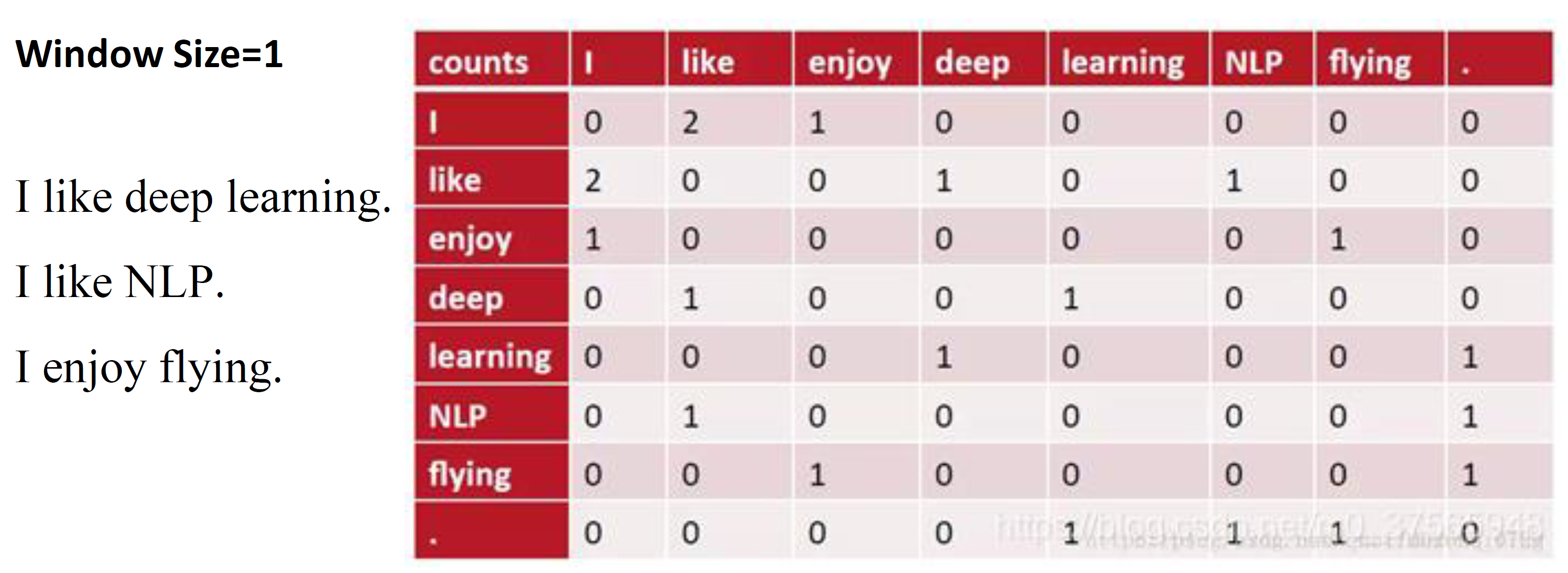
PMI
针对 Term-context
PMI(X,Y)=log2P(x)P(y)P(x,y)
PPMI在此基础上把 PMI 与 0 取 max。
w 为单词,c 为它的一个上下文单词。
PPMI=max(log2P(w)P(c)P(w,c),0)
若 P(w,c)=0 可加入平滑。
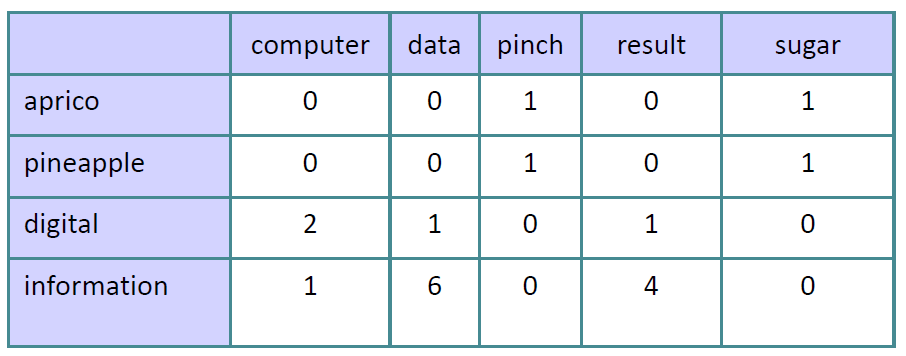 $$
P(\text{w=information},\text{c=data})=6/19=0.32\\
P(\text{w=information})=11/19=0.58\\
P(\text{c=data})=7/19=0.37\\
\text{PMI(information,data)}=\log_2\frac{0.32}{0.58*0.37}=0.58\\
$$
$$
P(\text{w=information},\text{c=data})=6/19=0.32\\
P(\text{w=information})=11/19=0.58\\
P(\text{c=data})=7/19=0.37\\
\text{PMI(information,data)}=\log_2\frac{0.32}{0.58*0.37}=0.58\\
$$
语义相似度
余弦相似度基于 PPMI
cos(v,w)=∣v∣∣w∣v⋅w
SVD
用于 Term-document matrix 数据降维。
对高维矩阵做奇异值分解,取权重最高的 K 维。
不足:
- 矩阵维度大小不固定,会随新词的添加而变化,语料库大小也随之变化。
- 矩阵过于稀疏,大部分单词不会同时出现。
- 矩阵维度太高。
- 训练成本太高。
- 需要加入一些隐含词来解决词频不均衡的问题。
神经网络预测方法
利用神经网络方法训练得到词向量。
与SVD可以有相同作用,但是计算量更低。
参考 https://blog.csdn.net/qq_34872215/article/details/88085288
词性标注
词性标注集:https://www.cnblogs.com/elpsycongroo/p/9369111.html
生成模型与判别模型
参考 https://blog.csdn.net/zouxy09/article/details/8195017
监督学习方法分为生成方法与判别方法,产生的模型称为生成模型与判别模型。
生成模型从数据集中学习到数据与标签的联合概率分布 P(x,y),之所以称为生成模型是因为可以根据这个联合概率分布自己生成一些 (x,y)。例如朴素贝叶斯和隐马尔科夫模型等。
判别模型学习到的则是条件概率分布 P(y∣x),即直接可以学习到在给定数据 x 的条件下,标签为 y 的概率,可以直接用来分类。例如k近邻,感知机,决策树,支持向量机等。
通过公式 P(x,y)=P(y)P(x∣y),生成模型可以得到判别模型,但判别模型不能得到生成模型。
马尔可夫模型
基于以下两个假设。
-
在时间 t 的状态只与其在时间 t-1 的状态相关。构成一个离散的一阶马尔可夫链。也就是满足上面提到过的一阶马尔可夫假设。
p(qt=Sj∣qt−1=Si,qt−2=Sk,⋯)=p(qt=Sj∣qt−1=Si)
-
不动性假设。状态与时间无关。即可以定义一个与时间无关的状态转移矩阵。
p(qt=Sj∣qt−1=Si)=aij
隐马尔可夫模型
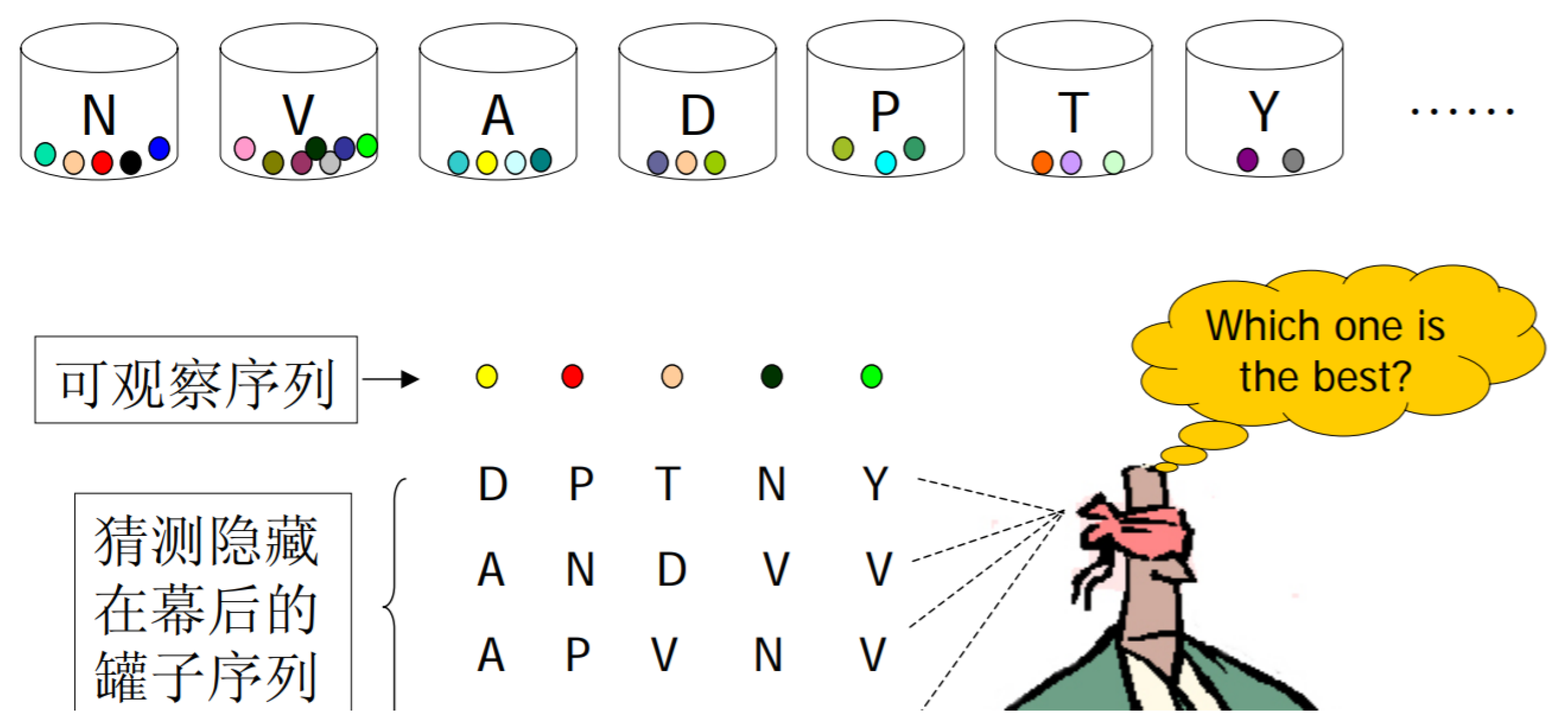
有多种状态,每一种状态都可能产生一些可观察事件,现在已知一个可观察事件的序列,要猜测状态转移的流程。
以上图为例,黄球和红球是两个可观察事件,N,V,A 等罐子就是一些状态。从黄球变到红球可能是从 罐子A 转移到 罐子 N,(因为罐子A里有黄球,N里有红球),但也可能是由 A 转移到 T,因为 T 里也有红球。这两种转移都是可能的,但我们并不知道究竟是哪一种。这就是HMM的定义描述中所说的“状态转换过程是隐蔽的”。
将模型描述为 μ=(S,O,A,B,π) ,即(状态序列,观察序列,状态转移概率矩阵,发射概率矩阵,初始状态概率分布),或 μ=(A,B,π)。
问题 1:给定模型 μ=(A,B,π) 和观察序列 O=O1O2⋯OT,快速计算 P(O∣μ) 。
令 Q=q1q2⋯qT 为状态序列。
p(O∣μ)=Q∑p(Q∣μ)×p(O∣Q,μ)
问题 2:给定模型 μ=(A,B,π) 和观察序列 O=O1O2⋯OT,得到最优状态序列 Q=q1q2⋯qT。
问题 3:给定一个观察序列 O=O1O2⋯OT,如何根据最大似然估计来求模型的参数值,即如何调节模型的参数,使得 p(O∣μ) 最大?
前向算法
dp[t][i] 表示在时刻 t,状态为 Si,出现观察序列 O1O2⋯Ot 的概率。
枚举 t−1 时刻状态,转移到 t 时刻状态,并在 t 时刻发射观察事件 O(t)。
复杂度 O(N2T),其中 N 为状态总数。
dp[1][i]=πibi(O1)dp[t][i]=(j=1∑Ndp[t−1][j]⋅aji)×bi(Ot)p(O∣μ)=i=1∑Ndp[T][i]
其中 bi(Ot) 表示在 Si 状态下出现观察事件 Ot 的概率,即发射概率。
后向算法
dp[t][i] 表示在时刻 t,状态为 Si,出现观察序列 Ot+1Ot+2⋯OT 的概率。
注意这里是在时刻 t 输出 Ot+1,也就是说在时刻 T 时什么都没有输出。
复杂度同前向算法 O(N2T)。
dp[T][i]=1dp[t][i]=j=1∑Naijbj(Ot+1)×dp[t+1][j]p(O∣μ)=i=1∑Ndp[1][i]×πi×bi(O1)
Viterbi搜索算法
其实就是输出上面的 dp 路径。
也就是在前向算法的基础上,再维护一个 fa[t][i]=k 表示 dp[t][i] 的最大值是由状态 qt−1=Sk 转移得到的。
复杂度必然也是同前向算法 O(N2T)。
HMM用于词性标注
即给定 词串 W,隐马尔可夫模型 λ,词性标注序列 T,求 P(T∣W,λ)。
以下计算都在模型 λ 的基础上,所以可以先去掉条件概率中的 λ,变为 P(T∣W)。
P(T∣W)=P(W)P(T,W)=P(W)P(T)P(W∣T)
得到
P(T∣W)∝P(T)P(W∣T)
结合马尔可夫模型的一阶假设
P(T)=P(t1∣t0)P(t2∣t1)⋯P(ti∣ti−1)
其中 P(ti∣ti−1)=训练语料中ti−1出现的次数训练语料中ti出现在ti−1后的次数
结合HMM的独立性假设(在状态 Si 下发射 wi 的概率独立)
P(W∣T)≈P(w1∣t1)P(w2∣t2)⋯P(wi∣ti)
其中 P(w_i|t_i)=\frac{\text{训练语料中w_i的词性被标记为t_i的次数}}{\text{训练语料中t_i出现的总次数}}
例:

再使用 Veterbi算法 得到最优词性标注序列。
逻辑回归最大熵
逻辑回归
是判别模型
P(y=1∣x,β)=1+exp(−∑i=1Fxiβi)1=1+e−x⋅β1
根据特征向量与系数向量的乘积得到概率。
从训练数据中学到系数向量。
特征选择不需要基于独立性假设。且可以选择任意与文章有关的内容。
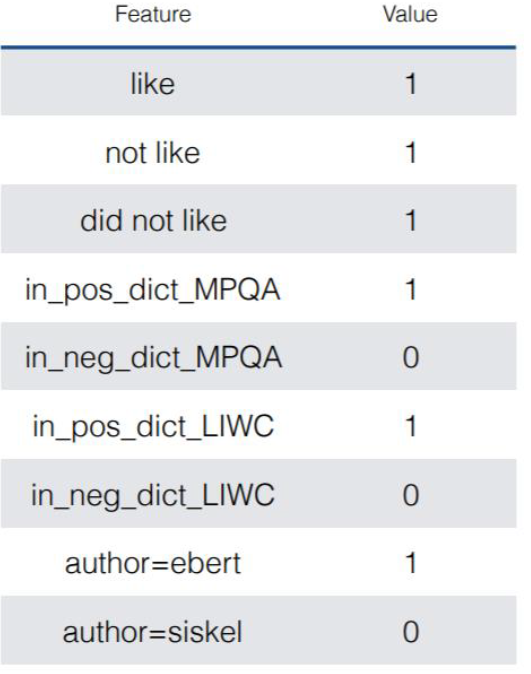
在测试时,对于一个 x,我们选择 argymaxP(y∣x),所以在训练时,我们希望得到系数 β 最大化正确标签的概率,根据极大似然估计,设定似然函数为 L(β)=i=1∏NP(yi∣xi,β),则要求得 argβmaxi=1∏NP(yi∣xi,β)。
逻辑回归用在语言模型
P(Y=y∣X=x;β)=∑iexp(xTβi)exp(xTβy)
即对 exp(xTβy) 的归一化。
Unigram LM
只有 BIAS 一维。

Bigram LM
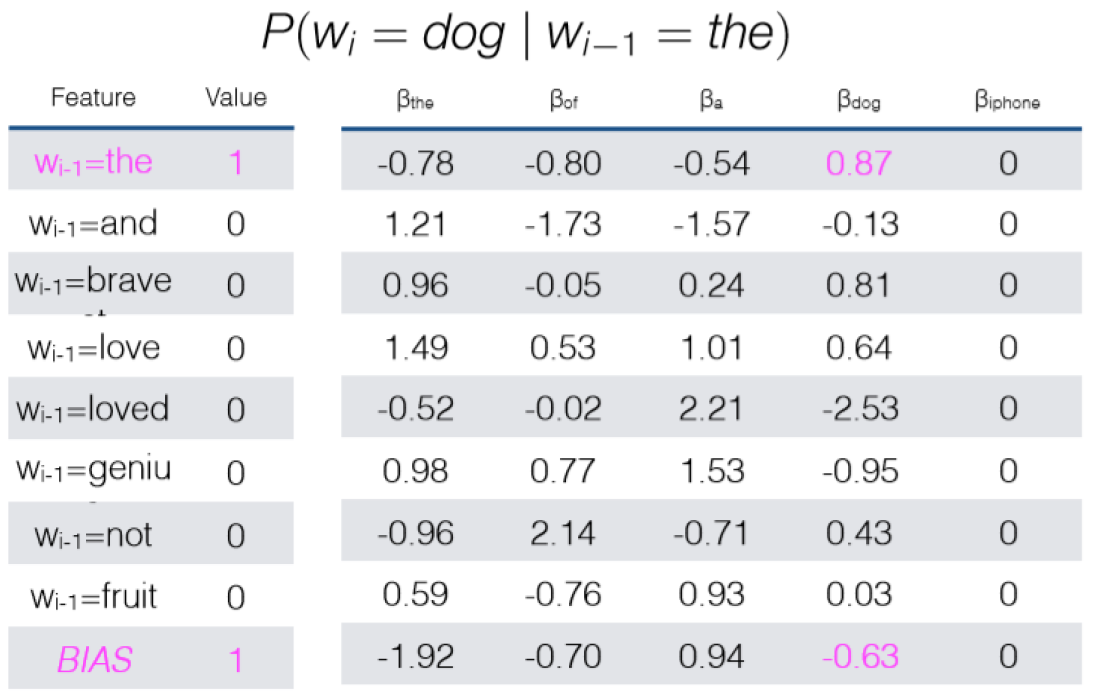
Trigram LM

平滑
增加一阶特征,即 P(wi∣wi−1)。
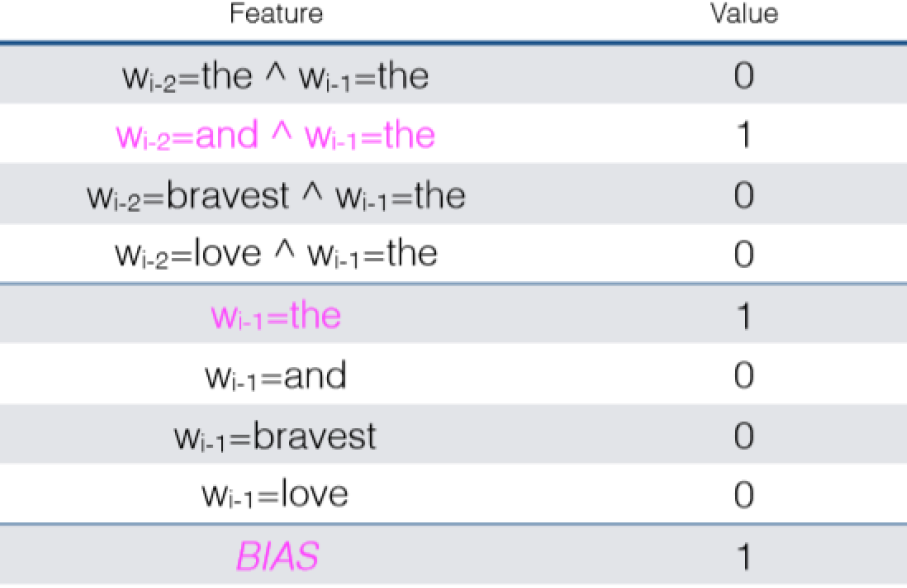
最大熵马尔可夫模型
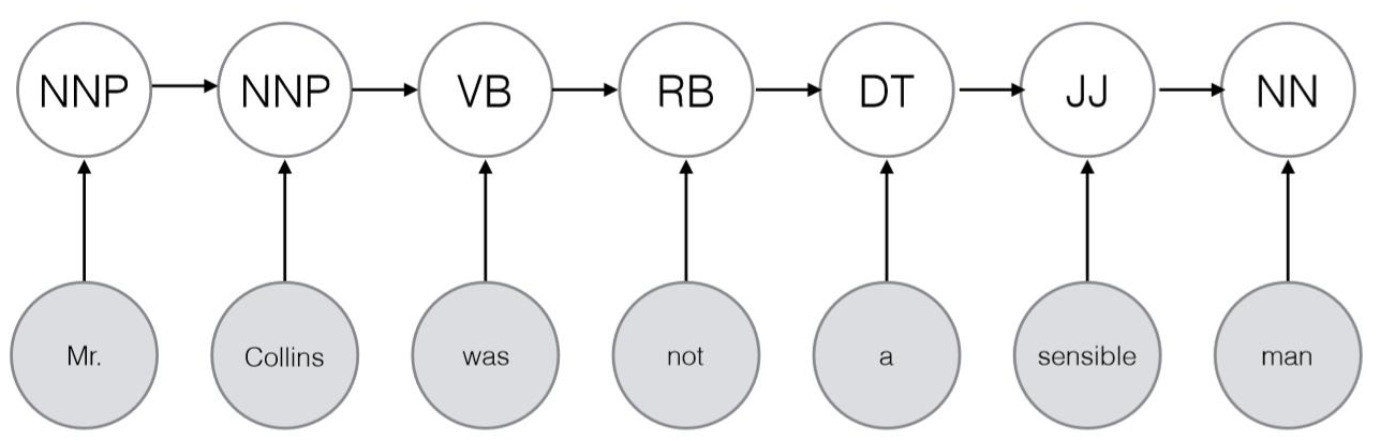
Viterbi算法
Viterbi for HMM:
vt(y)=u∈Ymax[vt−1(u)×P(yt=y∣yt−1=u)P(xt∣yt=y)]
Viterbi for MEMM:
vt(y)=u∈Ymax[vt−1(u)×P(yt=y∣yt−1=u,x,β)]
局部归一化
在 i=1∏nP(yi∣yi−1,x,β) 乘法的每一步都做归一化。
例如,设状态 MD->TO,MD->VB,则分别计算出 P(TO∣MD) 和 P(VB∣MD) 后,分别归一化变成 P(TO∣MD)+P(VB∣MD)P(TO∣MD) 和 P(TO∣MD)+P(VB∣MD)P(VB∣MD)。
局部归一化会导致 Viterbi 算法无法得到最优路径。
例如若 MD->TO,NN->TO,即这两种状态都是只能得到 TO,那么
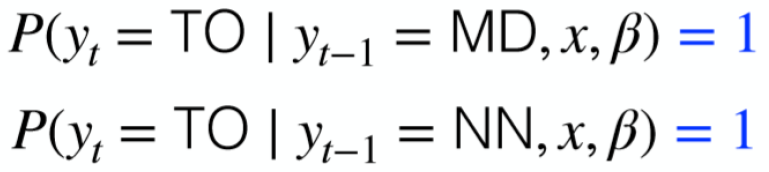
命名实体识别
命名实体:现实世界中具体或抽象的实体。如人,机构,地点等。广义地讲,命名实体还可以包含时间,日期,金钱等。需要在具体应用中判断。
包括基于字典/规则的命名实体识别方法,与基于统计的命名实体识别方法。
基于字典的命名实体识别方法
- 正向最大匹配算法
- 反向最大匹配算法
- 最短路径法(最少分词法)
与之前介绍的分词中的方法类似。
基于统计的命名实体识别方法
条件随机场(CRF)
定义:给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型。
特点:假设输出随机变量构成马尔可夫随机场。
应用:不同类型的标注问题,例如:单个目标的标注,序列标注,图标注。
HMM是生成式模型,难以考虑复杂的特征。HMM是概率有向图。
CRF是判别式模型,可以考虑复杂特征。CRF是概率无向图。
成对马尔可夫性
任意一对没有直接相连的节点,在给定其它所有节点 O 的条件下互相独立。
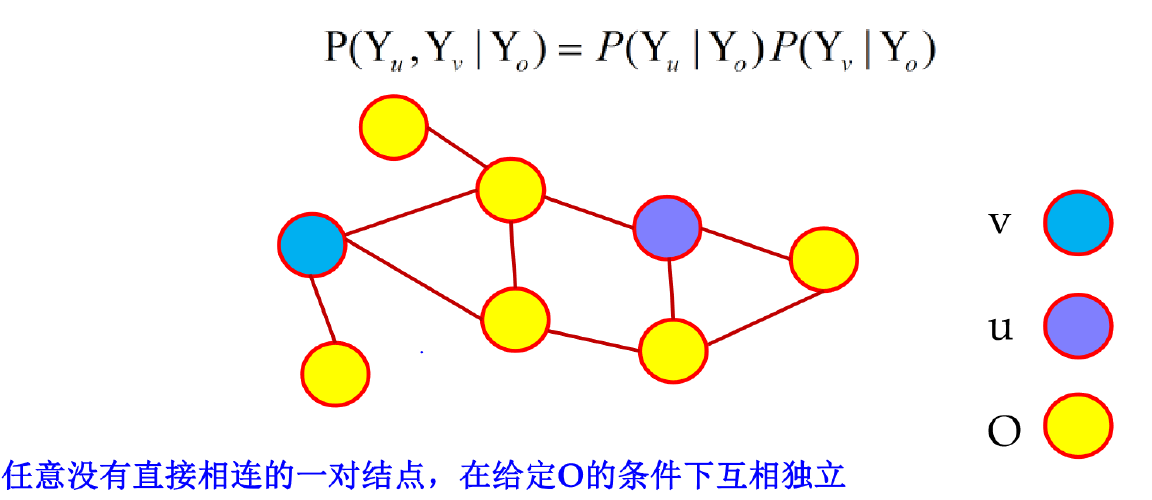
局部马尔可夫性
设 v 是图 G 中任意一点,O 是与 v 直接相连的所有点,U 是除 v,O 外的所有点,则给定随机变量组 Yo 的条件下 Yv 与 YU 独立。
任意一个节点与所有不与他直接相连的节点,在给定与他相连的节点组O的条件下,互相独立。
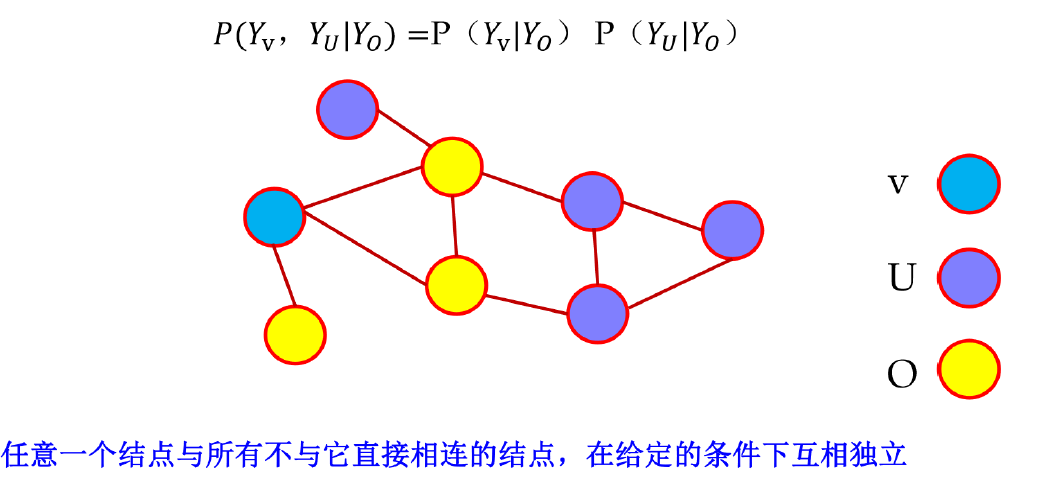
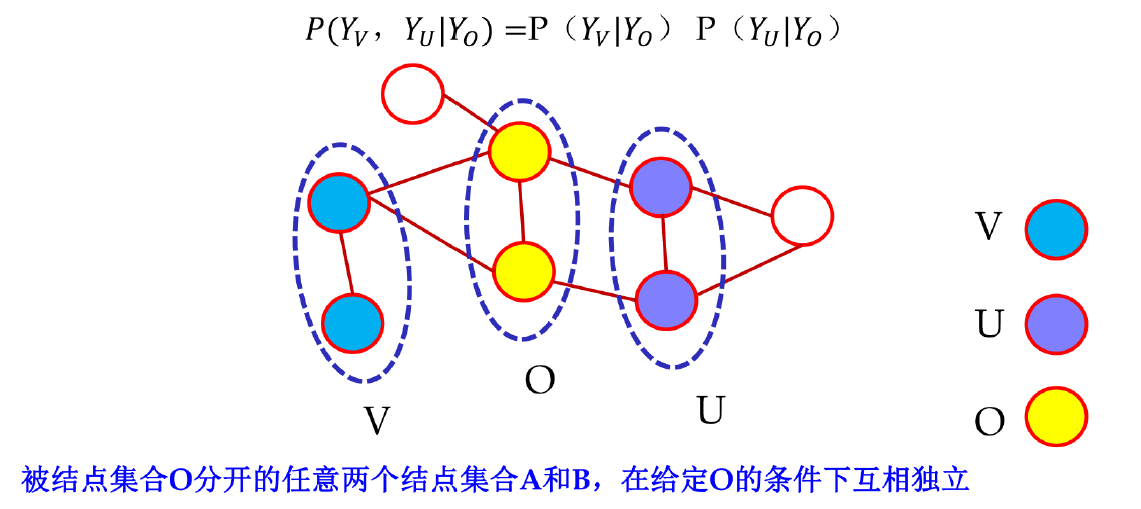
全局马尔可夫性
设节点集合 V,U 是被节点集合 O 分开的任意两个节点集合,则在给定 Yo 的条件下 YU 和 YV 独立。
马尔可夫随机场
如果概率无向图模型的联合概率分布 P(Y) 满足全部三种马尔可夫性,则称为马尔可夫随机场。
目的:将整体的联合概率分布 P(Y) 分解为若干子联合概率的乘积的形式,也就是进行因子分解。
最大团:不能再加进任何一个点使成为更大的团,则是最大团。并不一定只有整个图上包含点数最多的团。
因子分解:将马尔可夫随机场模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式。
设 C 是图 G 上的最大团,Ψc(Yc) 是 C 上的函数。则因子分解为
P(Y)=Z1c∏Ψc(Yc)
其中 Z 是归一化因子。
Z=Y∑c∏Ψc(Yc)
线性链条件随机场
条件随机场:若随机变量 Y 构成由无向图G表示的马尔可夫随机场,则称条件概率分布 P(Y∣X) 为条件随机场。
P(Yv∣X,Yw,w=v)=P(Yv∣X,Yw,w∽v)
其中 w∽v 表示与 v 直接相连的所有节点,w=v 表示除 v 以外的所有节点。
即 给定除 v 以外的所有点的条件概率分布 等于 给定与 v 相连的点的条件概率分布。
线性链条件随机场
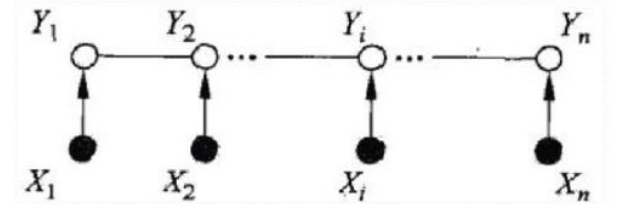
在条件随机场的基础上,X=(X1,X2,⋯,Xn),Y=(Y1,Y2,⋯,Yn) 均为线性链表示的随机变量序列。
P(Yi∣X,Y1,⋯Yi−1,Yi+1,⋯,Yn)=P(Yi∣X,Yi−1,Yi+1)
参数形式
上面说过,条件随机场是马尔可夫随机场,而马尔可夫随机场可以因式分解为最大团上的乘积。
在线性链条件随机场中,每一个相邻的点对都是一个最大团,所以条件概率分布可以表示为所有相邻点对上的函数的乘积。
下面取的函数为 exp 函数,所以相当于exp中指数的和。
P(y∣x)=Z(x)1exp(i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i))
Z(x)=y∑exp(i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i))
其中 x 为可观察样本的任意特征(例如:词本身,大小写,词性等),这里假设有 k 个特征,特征的重要程度由 λ 控制,训练得到。
tk 定义在边上的特征函数,也称转移特征,依赖于前一个和当前位置。
sl 定义在点上的特征函数,也称状态特征,依赖于当前位置。
例如:

解:
p(y∣x)∝exp[k=1∑5λki=2∑3tk(yi−1,yi,x,i)+k=1∑4μki=1∑3sk(yi,x,i)]λ1t1+λ5t5+μ1s1+μ2s2+μ4s4=1+0.2+1+0.5+0.5=3.2P(y1=1,y2=2,y3=3∣x)∝exp(3.2)
HMM vs CRF
- HMM 是一种生成式模型,利用转移矩阵和生成矩阵建模相邻状态的转移概率和状态到观察的生成概率。无法利用复杂特征(只有两个矩阵建模)。
- CRF是一种判别式模型,可以使用任意的复杂特征(特征函数)(虽然每个位置有一个矩阵,但是矩阵的元素是由特征函数和权重计算得到,我们可以任意地定义特征函数从而考虑各种特征),可以建模观察序列和多个状态的关系,考虑了状态之间的关系。
句法分析
上下文无关文法(CFG)
context-free grammar。
G=(N,Σ,R,S)
N ———— 非终结符构成的有限集合。如 NP,VP,S。
Σ ———— 终结符构成的有限集合。如 the,dog,a。
R ———— 产生式构成的集合,产生式的形式为 A→β,β∈(Σ,N),如 S→NP VP,Noun→dog。
S ———— 起始符号。
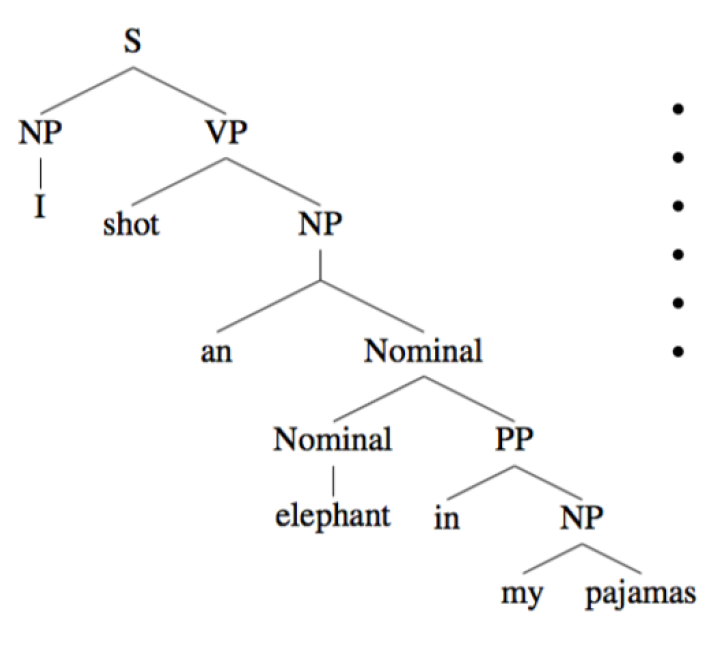
上下文无关文法中的产生式左侧的非终结符一定只能有一个符号。在每一个出现了产生式左侧的符号的地方都可以通过这个产生式替换为右侧的符号串,而不用考虑这个符号的上下文。
括号表示法
子树在一个括号里,终结符不需要再分隔。

评估
先表示为 {(label1,l1,r1),⋯,(labeln,ln,rn)} 的元组的集合形式,labeli 为标签,li 为第一个单词的下标,ri 为最后一个单词的下标。
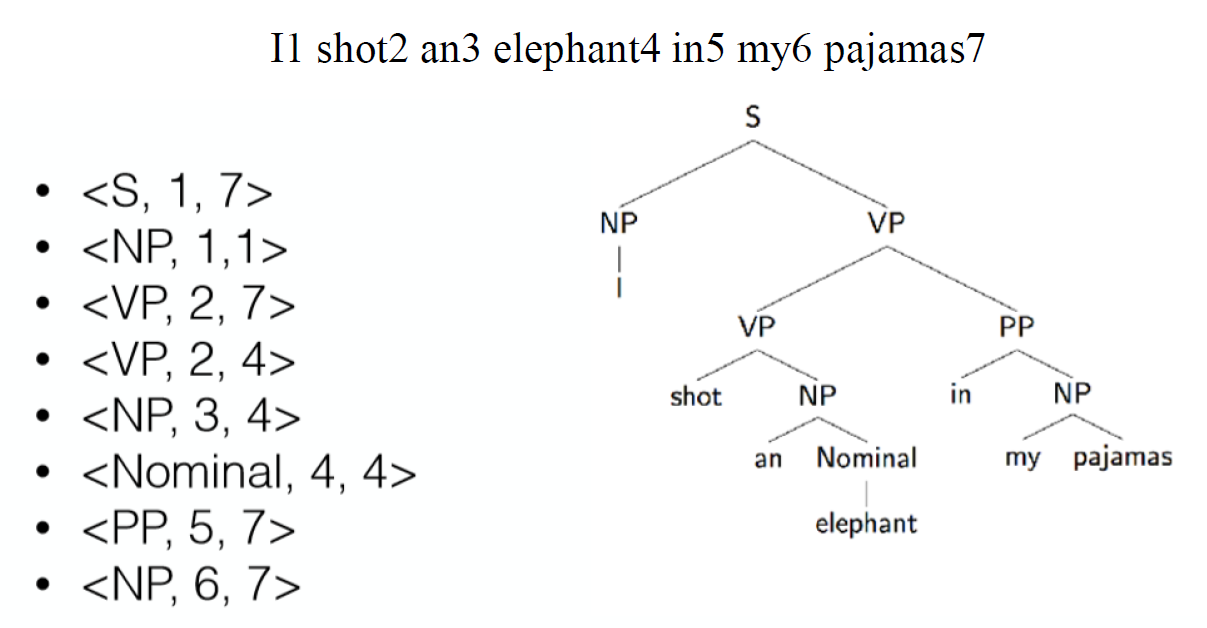
假设现在有2棵树,则
第一棵树的精确率Precision为 既在第一棵树中又在第二棵树中的元组个数 / 第一棵树中的元组个数。
第一棵树的召回率Recall为 既在第一棵树中又在第二棵树中的元组个数 / 第二棵树中的元组个数。
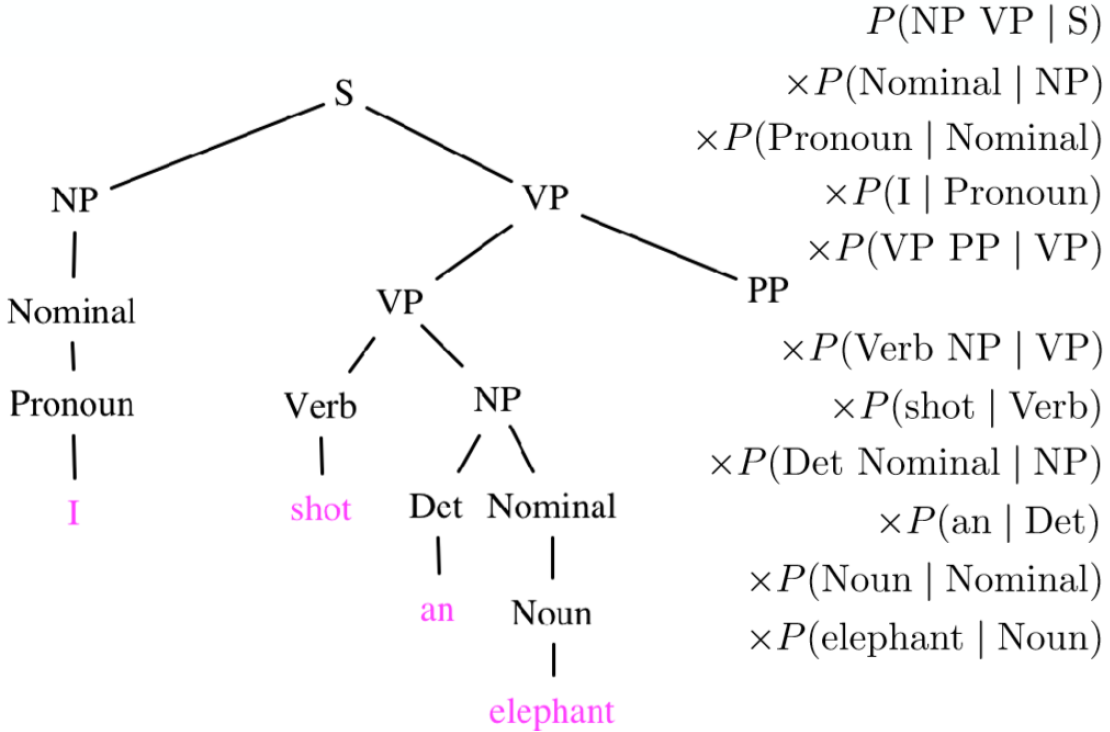
概率上下文无关文法(PCFG)
给定一个上下文无关文法,每个产生式都有概率。且对于每一种 A,都有
i∑P(A→βi)=i∑P(βi∣A)=1
给定一棵PCFG的树,就相当于每条边上都有边权是这条边代表的产生式的概率。
则由这棵树产生的句子的概率等于所有边权的乘积。
乔姆斯基范式(CNF)
G=(N,Σ,R,S)
N ———— 非终结符构成的有限集合。如 NP,VP,S。
Σ ———— 终结符构成的有限集合。如 the,dog,a。
S ———— 起始符号。
上面三个都与CFG相同。区别在于下面。
R ———— 产生式构成的集合,产生式的形式为 A→β。β 只能是 Σ 中的单个终结符,或者 N 中的两个非终结符。即树上节点要么有两个非叶节点儿子,要么只有一个叶节点儿子。
CKY算法
根据上面定义中的限制,原句子中的每个区间要么长度为1,要么只能由两个区间组合而成,所以就成了个典型的区间dp。
dp[i][j] 表示区间 [i,j] 能否用一个 N 或 Σ 中的符号表示。
则从小到大枚举长度,再枚举区间左端点,再枚举分割点,分割成两个已求出的区间进行转移。
CKY算法用于得到所有该句子可能的分解。
区间dp复杂度即为 O(n3)
基于PCFG的CKY算法
上面的CKY算法中 dp[i][j] 只能为 0/1。
加入概率,即 dp[i][j] 表示对区间 [i,j] 的众多分解方式中,概率最大的那个分解方式的概率。
问题与改进
问题:在不同位置的同一个产生式可能有不同的概率。
例如:位于主语位置的 NP ,产生DT NN的概率与位于宾语位置的NP产生 DT NN 的概率不同。
改进:在树上每个非叶节点上标注它的父亲,以此判断它所处的位置,并使用不同的概率。
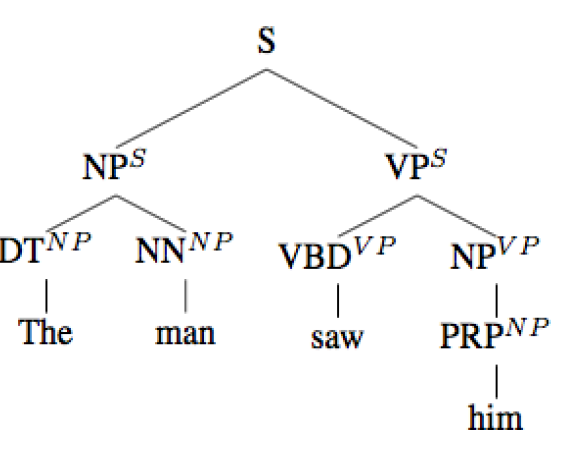
难点:使得语法非常臃肿,且数据集不够。
问题:叶节点无法影响树的概率。
例如:一条边 VBD->saw,换成 VBD->sneezed,树的概率不变。
改进:在每个非叶节点上标注它的子树中的一个关键的叶节点。
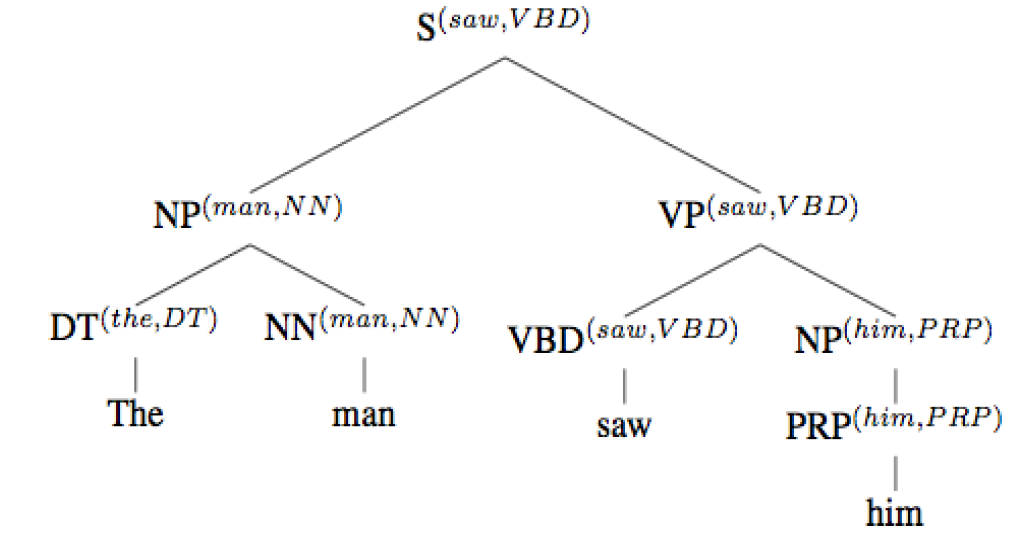
难点:不可能对每个终结符都已知概率。