
对word2vec模型的理解
这篇文章只是针对像我这种初学者大致理解word2vec模型的引导,并无数学推导!!
One-hot
对于一个词汇量为 V 的语料库,现在需要给每一个词分配一个向量,使得每个词汇的向量之间不会相互冲突。
One-hot 给出了一个 V 维的向量(V 为语料库的词汇数),每一个单词在向量中占一个位置,则每个单词的向量中有且仅有1位是1,其它都是0.
词嵌入
One-hot给出的词向量尽管两两不冲突,但实在是太过浪费,并且对于词汇来说,每个词汇都不应该是独立的,例如**“我,和,你”,这三个词常常会出现在一起,则我们只要看到“我,?,你”,都能够推出中间那个词应该是“和”,而One-hot却将每个词汇独立出来,即“我”,“和”,“你”**之间变得毫无关系,这在文本情感分析中是致命的。
现在我们的任务是找出一种词汇的向量表示法,使得:
- 不同词汇的表示不会产生冲突。
- 词向量的维度尽可能地小。
- 对于有上下文关联的词汇,它们的词向量也应该有某种关系。
将One-hot所表示的高维度词向量嵌入低维度的空间,这样的方式叫做词嵌入。
Word2Vec模型
Word2Vec就是一种词嵌入模型。
Word2Vec有两种类型:CBOW 和 Skip-Gram
CBOW(Continuous Bag-of-Words)
对于每一个词 ,我们假设现在需要它受到 m 个上下文单词的影响。则都应该被列为我们的考虑范围(注意,上述的 m 是指上下文范围的半径)。
先给出CBOW的模型图,再来理解
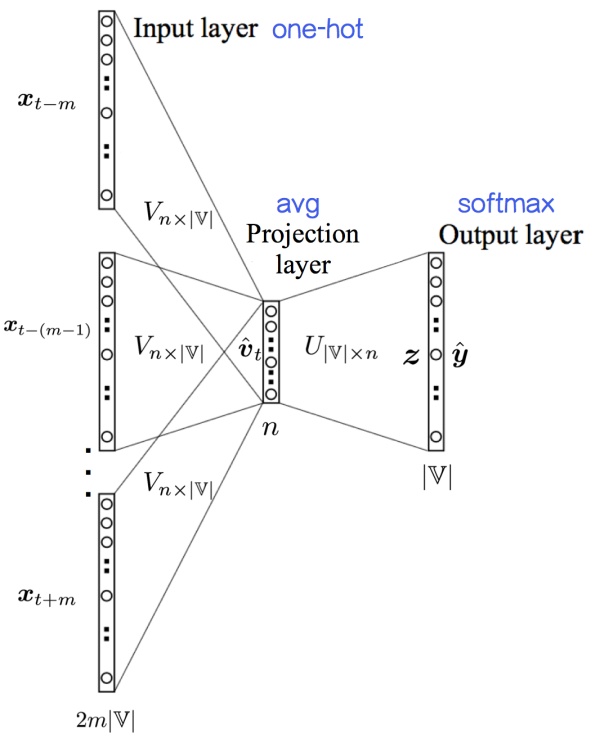
可以看到,输入层为 到 在语料库中的 One-hot 向量,而输出层是 V 个单词的在此位置的出现概率,在这里给出CBOW模型的目的。
CBOW模型根据上下文推测‘当前位置应该是什么单词。
上文说过V是语料库的词汇数,那么输出的是每一个词汇应该出现在当前位置的概率。
但是,得到输出并不是CBOW模型的最终目的!!
还记得上文说我们的目的是要的到一个词汇的向量表示法,满足以上给出的三个条件吗?
我们需要的是从输出层到隐藏层的权重矩阵 ,这里的 ,就是我们最终得到的词向量的维度,由于有 行,所以每一行对应一个单词的词向量,每个词向量有N维。
则这个权重矩阵 就相当于一个字典,我们把一个单词的One-hot乘以这的权重矩阵 ,就得到了这个单词的词向量。实际上这个权重矩阵也就叫"Look Up Table".
接下来,要怎么求解得到这个权重矩阵?
先初始化一个权重矩阵。
接着如图上所示,对于每一个单词输入它的上下文单词在语料库中的One-hot向量,乘以权重矩阵,得到一个 维的矩阵,或者说得到 个 维的向量,则对这 个向量相加,求均值,再用Softmax,乘以输出矩阵,得到输出层。对照实际值Label,根据Softmax的交叉熵损失函数,修正权重矩阵。
附交叉熵损失函数:
其中 是真实分布概率, 是模型计算出的概率。
上述过程一定不陌生,因为这就是训练神经网络的普遍方法,实际上也正是如此,CBOW模型就是一个有1层隐藏层的神经网络。
最终我们得到了权重矩阵 ,再次强调,输出层只是副产物,我们的主要目的是得到 这个"Look Up Table"。
Skip-Gram模型
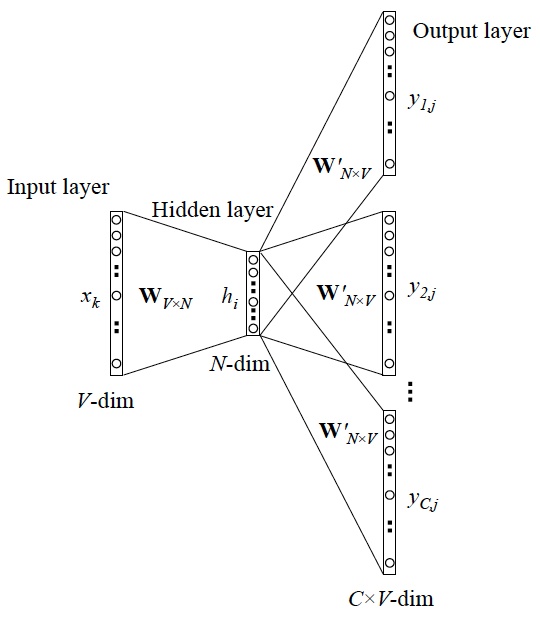
Skip-Gram模型与CBOW模型相反,是根据当前位置的单词,猜测它的上下文单词。
由于本文主要为了得到词向量,所以对这个模型不再解释。
因为我也不会